Data science 101 for lawyers
What is data science?
Data science has been defined as:
The exploration and quantitative analysis of all available structured and unstructured data to develop understanding, extract knowledge, and formulate actionable results.
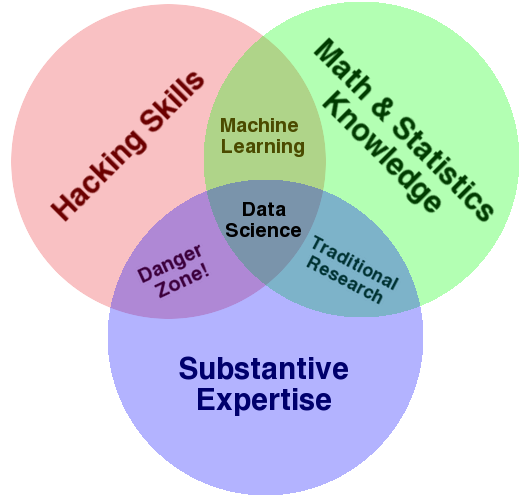
Drew Conway’s ven diagram has become quite famous, although as Jake VanderPlas says:
While some of the intersection labels are a bit tongue-in-cheek, this diagram captures the essence of what I think people mean when they say “data science”: it is fundamentally an interdisciplinary subject. Data science comprises three distinct and overlapping areas: the skills of a statistician who knows how to model and summarize datasets (which are growing ever larger); the skills of a computer scientist who can design and use algorithms to efficiently store, process, and visualize this data; and the domain expertise—what we might think of as “classical” training in a subject—necessary both to formulate the right questions and to put their answers in context.
What is a data scientist?
There are different kinds of data scientists. This course has been described as an intro to data wrangling because data science is a profession in itself and clearly out of scope. This is meant to be an introduction for people interested in learning to swim in data and collaborate with others people in that field. In terms of the law, we can think of data as evidence over opinion, the facts. Lawyers have been defining and refining the laws of evidence for centuries so in that sense, they are uniquely qualified.
think of data science not as a new domain of knowledge to learn, but a new set of skills that you can apply within your current area of expertise.
~ Jake VanderPlas
The discipline of data science is better defined by looking at what they do.
What data scientists spend time doing
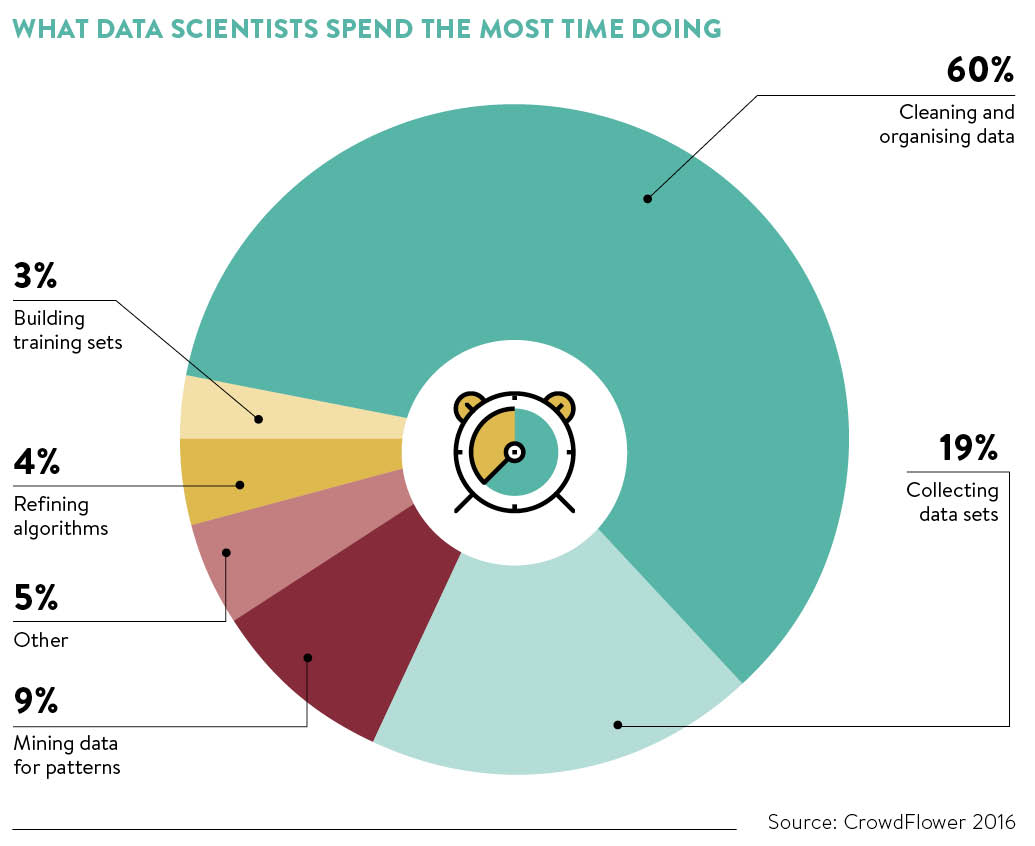
This looks very much like discovery in a large trial or investigation. Trawling through mounds of evidence or unused material is a common legal experience. However, the art of data wrangling has been taken to a whole new level in the age of big data and mass paralell processing. There is much to learn and anyone that thinks they have a handle on current techonology are probably doing it wrong.

Data scientists are obsessed with data
- Finding data sources
- Acquiring data
- Cleaning and transforming data
- Understanding relationships in data
- Delivering value from data
- Visualizing data and results
- Building data products
Data scientists think analytically
Make decisions based on analysis of data:
- Replace intuition with data driven analytical decisions
- Formulate and test hypothesizes based on their analysis
- Transform raw data into valuable assets
- Extract value from data assets
- Increase the pace of decisions, actions and knowledge acquisition
Legal text analytics
- Over 80% the world’s data is unstructured text
- NLP, Information extraction & retrieval (IR), library science data science is the most challenging area of data science (believe it…far more challenging than vision, genomics and others specialties)
- Human knowledge is at the center of everything
- Text Mining is the reason Google, Microsoft, Facebook, Twitter, LinkedIn, Amazon and others dominate in every area of analytics
Text analytics… refers to the discovery of knowledge that can be found in text archives… [it] describes a set of linguistic, statistical and machine learning techniques that model and structure the information content of textual sources for business intelligence, exploratory data analysis, research or investigation. (Hu and Liu, 2002, pp 387-8). When the texts to be analyzed are legal, we may refer to “legal text analytics” or more simply “legal analytics”.
~ Kevin Ashley, AI and legal analytics

Pioneers… before the internet
- 1964 – 1967 Ohio Bar Automated Research (OBAR) writes the specification for an online, interactive, computer-assisted research service
- 1964 Data Corporation in Dayton contracted to implement what would become the LEXIS service
- 1973 LEXIS is unveiled and goes on to take 75 percent of the computerized legal research market by the late 1980s
- 3 petabytes of data which doubles every three years (150 times size of wikipedia)
Where to start?
Swami Chandrasekaran posted this excellent map in his article on becoming a data scientist:

Scikit-learn also have this great map with links out to descriptions of each estimator.

To become data artisans we need tools!
- Flexible and composable, many good libraries and interoperability with a large ecosystem of frameworks
- Rapid and iterative prototype, develop and productionize
- Tools that span the entire Knowledge Discovery lifecycle
- Great documentation, reference material and examples
- Large community of practitioners
- Easy to learn
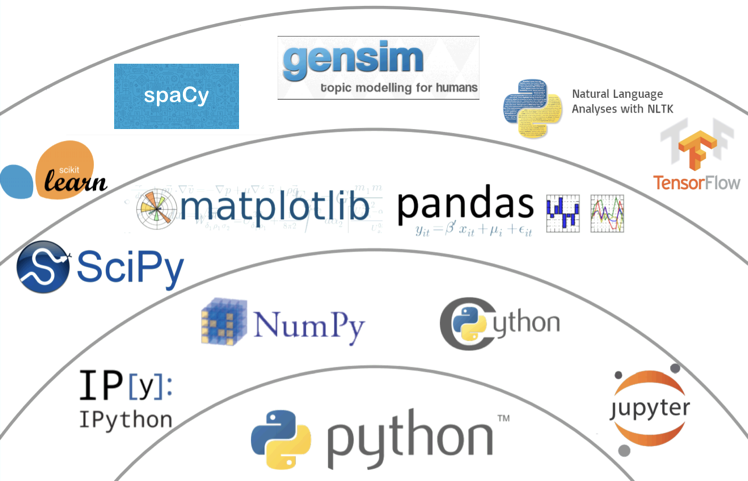
What about R? Apache Spark? Others?
Some argue:
Python is the last language you’ll have to learn
- Python vs. R can get “religious” but here are a few reasons to stick with Python (for now):
- Any R Library from Python with RPy2: https://rpy2.readthedocs.io
- Python is a 1st class language in Apache Spark and libraries like SciKit-Learn and TensorFlow are already ported to Spark
- Every major Deep Learning framework released in the last 2 years is based on or has 1st class support for Python (Theano, Caffe, Torch, TensorFlow and many others)
- The same is not true for R
- More importantly, Python’s language and ecosystem give you many powerful tools in a lightweight, extensible and portable toolkit
Let’s build and explore our toolkit!
When we ran pip install ipdb it also installed some other useful things like jupyter notebooks
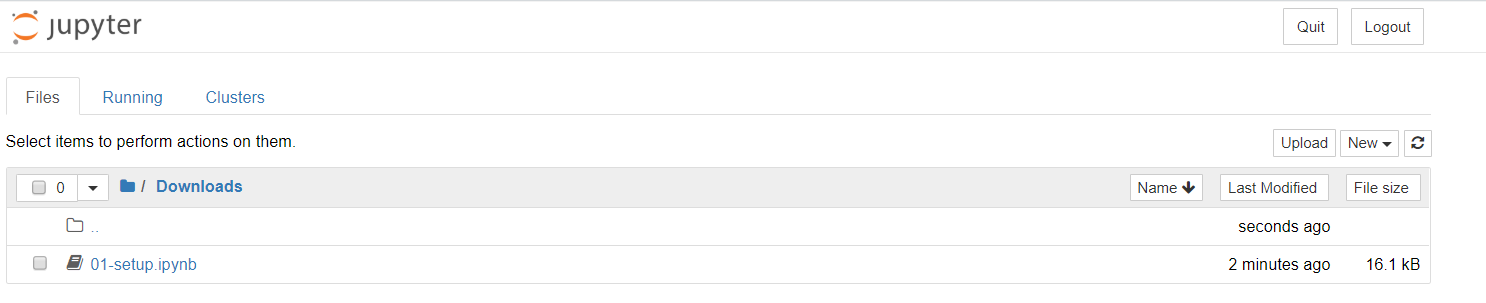
- Go to the terminal and run
jupyter notebook
If this does not work run pip install jupyter notebook and try again. It should start running on your local browser at: http://localhost:8888/tree.
- Navigate to the http://localhost:8888/tree/Downloads directory
- Download and run 01-setup.ipynb
- Check out this ever-growing gallery of interesting Jupyter Notebooks